


The Generative AI journey (part 1)
From standalone to compound to agentic AI.

Standalone Generative AI
In the beginning, there was standalone Generative AI.
People interacted with tools like ChatGPT—the most popular large language model (LLM)—by crafting prompts and sometimes uploading documents as contextual input. This approach worked remarkably well for many “one-off” tasks knowledge workers faced daily. It’s safe to say that this remains the starting point for the majority of users; even today.
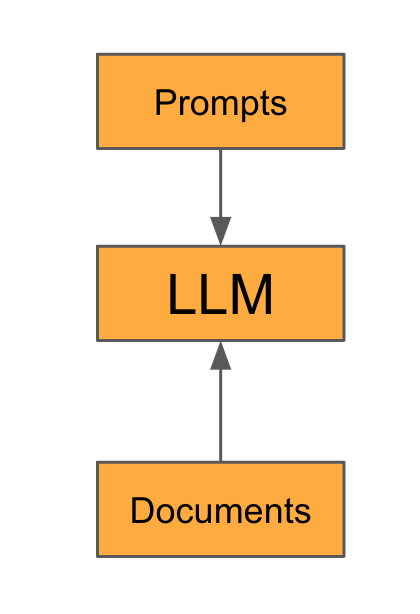
However, since 2023, the landscape has evolved rapidly. Innovations have been introduced to maximize the impact of Generative AI while addressing its limitations and risks.
Compound Generative AI
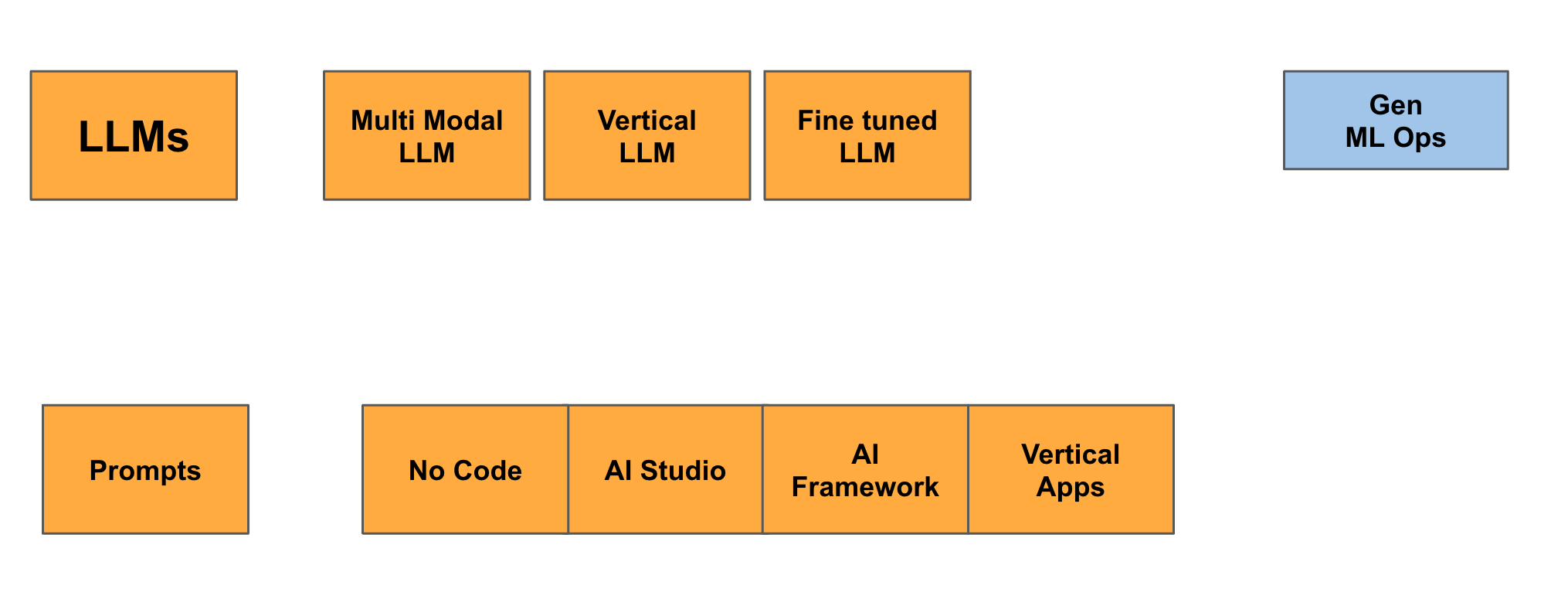
LLMs, by design, are generic tools. But generic doesn’t always mean optimal. To address specific use cases, a growing number of specialized models have emerged, fine-tuned for particular domains or data types. For instance, Med-PaLM outperforms general-purpose models in healthcare, while Claude excels in text generation and Gemini stands out in image analysis.
Today, users often switch between multiple models based on the task at hand.
My personal toolkit includes GPT, Claude, and Perplexity for daily tasks, while Gemini has proven invaluable for certain client projects.
In some cases, the requirements of a task are so specific that standard models fall short. This is where fine-tuning enters the picture. While fine-tuning has become less popular in 2025 due to advances in extended context capabilities, it remains a valuable tool when precision is critical.
The evolution of LLMs has been marked by increasing specialization, enabling them to tackle a more diverse array of challenges.
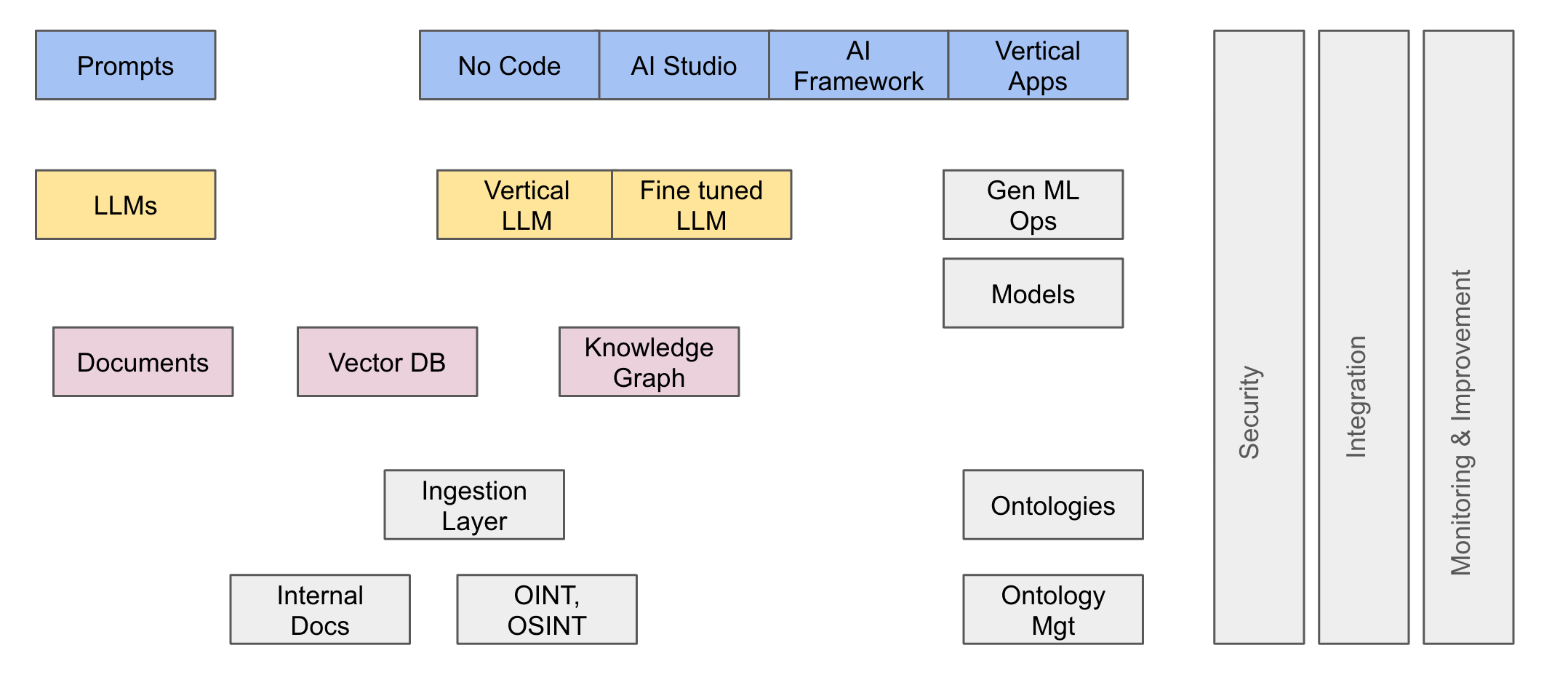
Nevertheless, this is how the LLM layers has evolved over the years to address the diversity of problems to tackle:

Beyond Standalone Prompts
From a productivity standpoint, standalone prompts, while powerful, are not a panacea. Users now need to:
Reuse and refine prompts.
Share prompts with teams.
Develop multi-user applications with complex workflows.
OpenAI’s GPTs, which allowed users to package LLMs, prompts, and documents (in Retrieval-Augmented Generation, or RAG, style), represented an early attempt to address these needs. They didn’t gain significant traction and they are back at it with Tasks.
At the enterprise level, the demands are far greater. Organizations require environments to safely create and deploy a wide range of LLM-powered applications:
No-code platforms for business users to build and share simple applications without needing developers.
AI studios for more complex tasks, where developers can incorporate additional AI components, such as prompt sanitization or anonymization.
Full frameworks for developing robust, enterprise-grade applications, often relying on verticalized or fully packaged solutions.
To address the complexities of scaling Generative AI applications, companies are investing in GenAI MLOps frameworks that manage prompt workflows, monitor hallucination rates, and ensure models stay aligned with enterprise objectives.
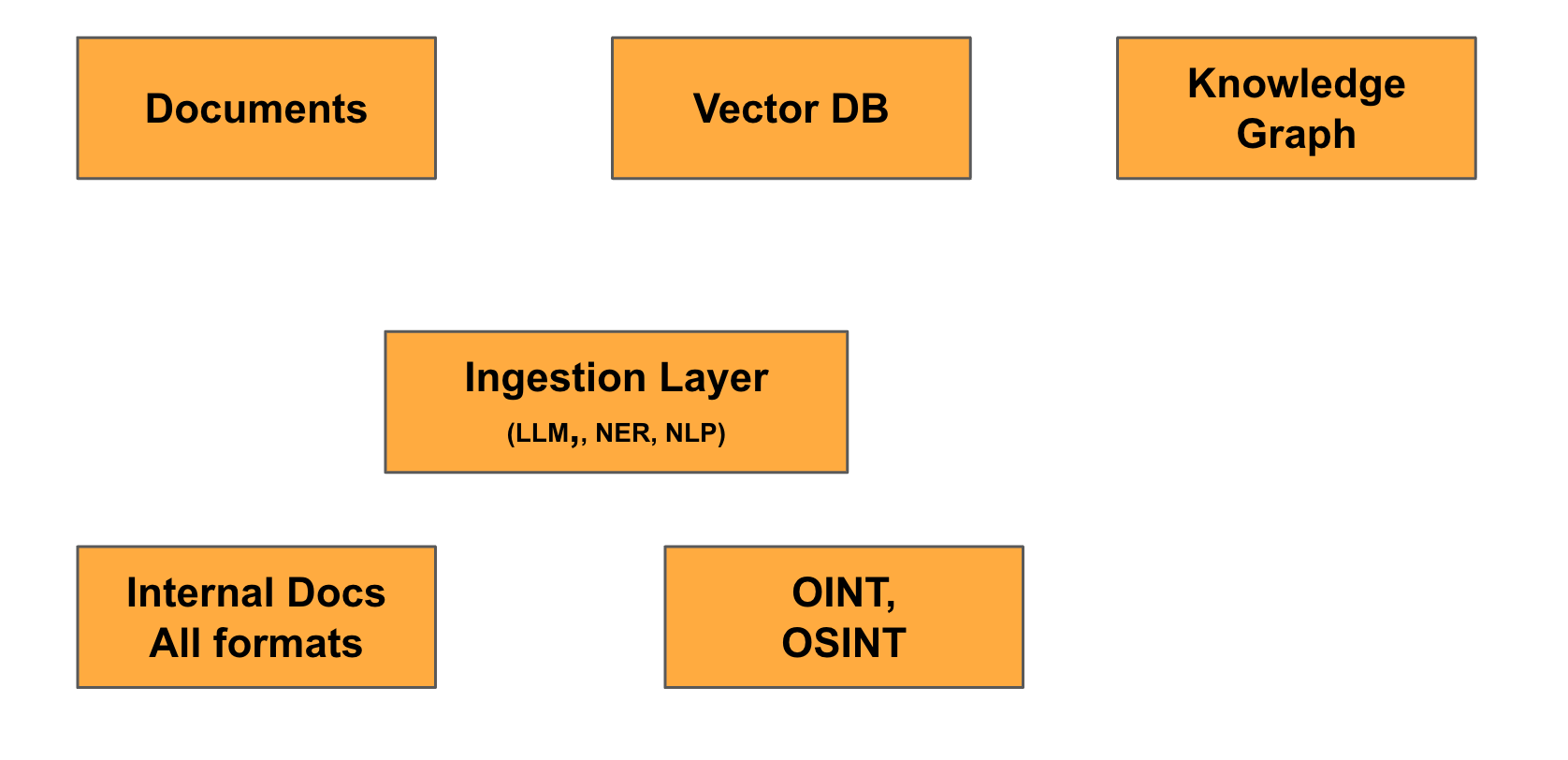
The Role of Data and Context
One undeniable truth about LLMs is their propensity to hallucinate—they are, by design, predictive models rather than truth engines. The only way to ensure reliable outputs is to ground their responses in context. And it’s even not guaranteed.
But context has limits. The volume of data an LLM can process in a single interaction is finite (even as this limit grows). To address this, organizations have developed:
Databases to store and retrieve relevant content on the fly.
Semantic databases and embeddings for efficient information retrieval.
Raw content alone, however, is insufficient for more advanced reasoning.
The next frontier lies in feeding LLMs structured data, such as Knowledge Graphs, which allow for richer, context-aware interactions and a much better strategy to fight hallucinations.
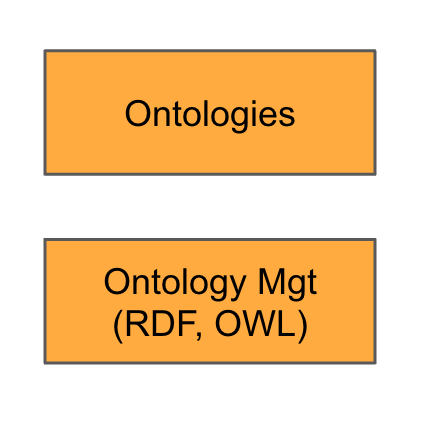
Knowledge Graphs are transformative because they provide LLMs with a structured view of the world. For example, deciding whether an “address field” is represented as street/city/country or as geographic coordinates (latitude/longitude) can significantly impact the model’s precision, privacy compliance, and overall utility.
This is where ontologies come into play, optimized either for retrieval or reasoning depending on the need.
Beyond the Essentials
In addition to data, other critical components are required for a functioning Generative AI ecosystem:
Security and governance to protect sensitive data and ensure ethical use.
Integration with existing enterprise systems for seamless workflows.
Monitoring (both automated and human) to ensure performance remains consistent and aligned with objectives.
and voilà !
This evolution from standalone to compound Generative AI has laid the groundwork for the next stage: Agentic AI, where systems will act autonomously, leveraging diverse data sources and reasoning capabilities to deliver transformative outcomes. Stay tuned for Part 2.